DeepSeek DSpark 投机解码原生集成 vLLM,性能提升显著 最近,D...
DeepSeek DSpark 投机解码原生集成 vLLM,性能提升显著
最近,DeepSeek 和 vLLM 的合作让 AI 推理速度有了显著提升。这种提升不是简单的优化,而是一种全新的解码方式带来的质变。如果你对 AI 如何更快生成文本感兴趣,这篇文章值得你花时间阅读。
什么是投机解码?
投机解码(Speculative Decoding)是一种让 AI 模型更快生成文本的技术。想象一下,你写文章时不是一字一字地敲,而是先快速写下几个可能的句子,然后选择最好的那个继续。AI 模型现在也在学习这种"先猜后选"的方式。
传统解码方式像是在一条单行道上行驶,每一步都必须确认无误才能前进。而投机解码则像是开辟了多条小路,同时探索多种可能性,然后选择最佳路径继续。这种并行探索的方式大大提高了效率。
DSpark 是什么?
DSpark 是 DeepSeek 开发的一种半自回归草稿模型。这个名称听起来复杂,其实我们可以拆解理解:
"半自回归"意味着它不完全像传统模型那样一步一步生成文本,而是可以同时生成多个可能的 token(文本的最小单位)。
"草稿模型"则表明它生成的不是最终文本,而是类似于写作时的草稿,需要进一步验证和选择。
DSpark 的核心创新在于使用了"非因果滑动窗口注意力"技术。这听起来很专业,其实我们可以用一个简单的类比来理解:
想象你在读一本书,传统模型会从第一页开始,一页一页顺序阅读。而 DSpark 则像是在书页上放了一个放大镜,可以同时看到前后几页的内容,这样就能更好地理解上下文,并预测接下来的内容。
DSpark 如何工作?
DSpark 的工作流程可以分为几个步骤:
这个过程就像是一个团队协作:一个人提出多个可能的方向,团队快速评估后选择最佳方向,然后所有人朝这个方向前进,而不是一个人一步一步慢慢走。
性能提升有多大?
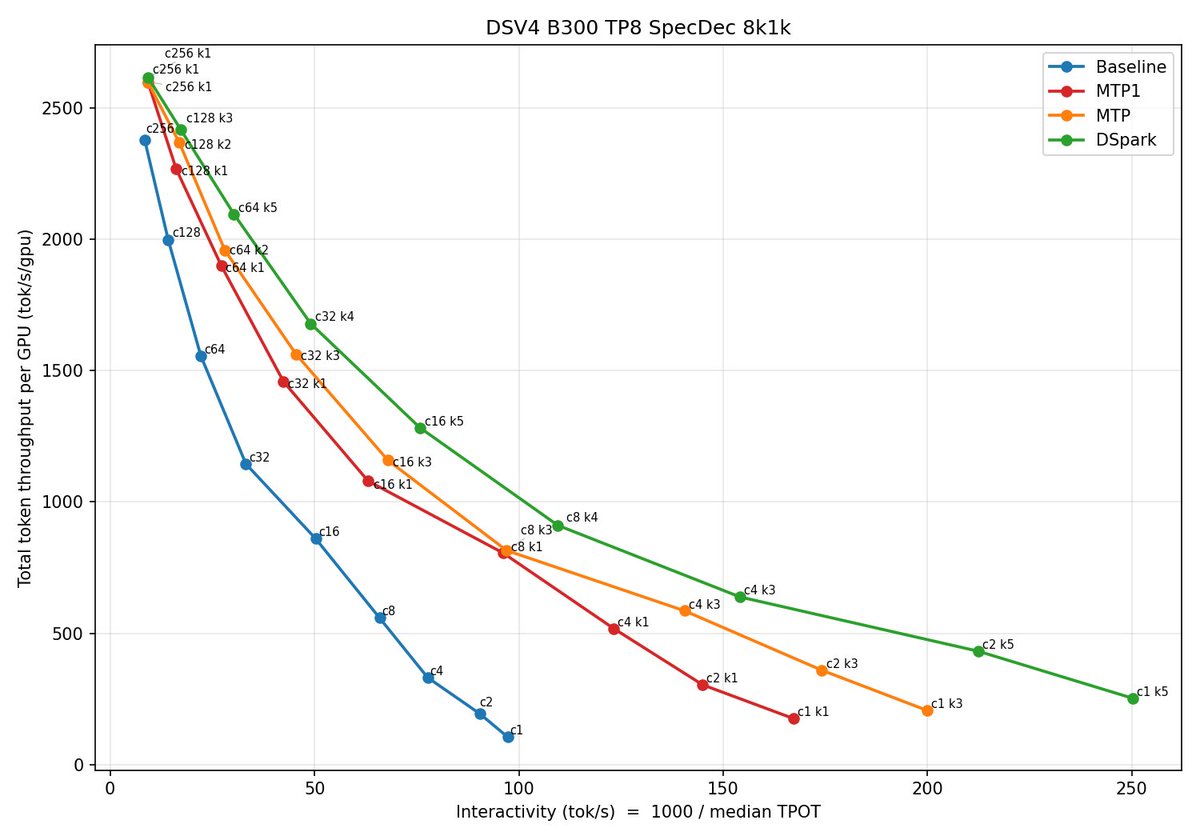
在测试中,DSpark 表现令人印象深刻。在 NVIDIA 8×B300 GPU 上,DeepSeek-V4-Pro-DSpark 在 batch size 1 时达到约 250 tokens/s。
这个数字说明的是,每秒可以处理约 250 个文本单元。对于普通用户来说,这意味着更快的响应时间;对于企业应用,这可能意味着更高的吞吐量和更低的成本。
更值得注意的是,DSpark 在不同草稿深度下比 MTP(另一种投机解码方法)的接受率高 12-42%。这个差距在 AI 领域已经算是非常显著的了。
vLLM 如何实现这一集成?
vLLM 作为流行的推理框架,通过多种技术实现了对 DSpark 的原生支持:
这些技术听起来很专业,其实核心思想都是"减少重复计算"和"优化内存使用"。就像我们在写作时会保存常用的句子模板,AI 模型现在也在学习如何"记住"和"重用"计算结果。
这有什么实际意义?
对普通用户来说,这意味着更快的 AI 响应时间。想象一下,你问一个问题,AI 几乎是瞬间回答,而不是等待几秒钟。
对开发者来说,这意味着可以在不增加硬件成本的情况下提高服务能力。同样的服务器,现在可以处理更多的请求。
对整个行业来说,这可能标志着 AI 推理效率进入了一个新阶段。随着更多类似技术的出现,AI 的应用场景将更加广泛。
未来会怎样?
现在下结论为时尚早,但 DSpark 和 vLLM 的集成无疑展示了投机解码技术的巨大潜力。随着更多优化和改进,我们可能会看到更高效的 AI 推理方式。
区别在于,这次的技术突破不是来自算法的微小改进,而是来自对传统解码方式的根本性重新思考。这种范式转变往往能带来意想不到的突破。
值得持续跟踪的是,这种技术是否会成为行业标准,以及它将如何影响 AI 应用的普及和成本。
随着 DSpark 投机解码技术的普及,我们是否正在迎来一个 AI �